


Создание семантического ядра на автомате при помощи сервиса Rush Analytics
admin
Создание семантического ядра - это важное и кропотливое дело – фундамент сайта, который должен быть прочным. В то же время это нудное и монотонное занятие, во многом такое же унылое, как просмотр фильма "Пятьдесят оттенков серого" ;)
Нужно собрать подсказки в поисковиках. Затем проверить каждый ключ на частотность и отсеять неподходящие. Прежде, чем будет готов расширенный список ключей для ядра, пройдут часы. А затем их надо еще и сгруппировать. Все это, я подробно уже разбирал в большой статье о самостоятельном создании семантического ядра.
 Сегодня, я хочу рассказать про автоматизацию этого процесса, а именно Rush-analytics – сервис автоматизированного сбора семантического ядра. С его помощью всего за несколько минут можно собрать подсказки Яндекса и Google, получить информацию о частотности запросов и кластеризовать их. Рекомендую почитать больше про Rush Analytics - цены, инструкции, функционал и многое другое.
В этом обзоре мы протестируем сервис и узнаем, действительно ли он быстро и точно собирает ядро и экономит время веб-мастера.
Оглавление:
Приступим!
Сразу после регистрации на сайте rush-analytics.ru нас ждет сюрприз. Система дарит каждому пользователю 200 рублей на счет для тестирования сервиса.
В интерфейсе сложно не разобраться. В правом верхнем углу информация по аккаунту, состояние счета и дополнительная информация по сервису. вверху слева.
Сегодня, я хочу рассказать про автоматизацию этого процесса, а именно Rush-analytics – сервис автоматизированного сбора семантического ядра. С его помощью всего за несколько минут можно собрать подсказки Яндекса и Google, получить информацию о частотности запросов и кластеризовать их. Рекомендую почитать больше про Rush Analytics - цены, инструкции, функционал и многое другое.
В этом обзоре мы протестируем сервис и узнаем, действительно ли он быстро и точно собирает ядро и экономит время веб-мастера.
Оглавление:
Приступим!
Сразу после регистрации на сайте rush-analytics.ru нас ждет сюрприз. Система дарит каждому пользователю 200 рублей на счет для тестирования сервиса.
В интерфейсе сложно не разобраться. В правом верхнем углу информация по аккаунту, состояние счета и дополнительная информация по сервису. вверху слева.
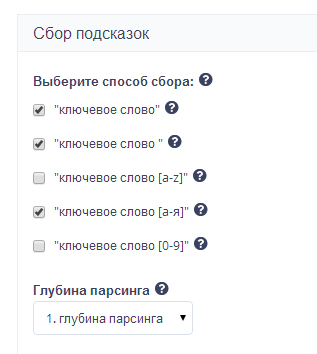 Наводим курсор на знак вопроса – открывается желтое окно, в котором указана информация по каждому из способов. Также в этой вкладке мы указываем глубину парсинга.
Изначально глубина стоит на отметке «1». Это означает, что система соберет подсказки лишь один раз, основываясь на заданных вами ключах. Установите «2» и тогда система пройдется по второму кругу, собирая подсказки по ключам, полученным после первого круга.
Оставим все как есть и перейдем к третьему шагу.
Открываем вкладку «Ключевые слова и цена».
Наводим курсор на знак вопроса – открывается желтое окно, в котором указана информация по каждому из способов. Также в этой вкладке мы указываем глубину парсинга.
Изначально глубина стоит на отметке «1». Это означает, что система соберет подсказки лишь один раз, основываясь на заданных вами ключах. Установите «2» и тогда система пройдется по второму кругу, собирая подсказки по ключам, полученным после первого круга.
Оставим все как есть и перейдем к третьему шагу.
Открываем вкладку «Ключевые слова и цена».
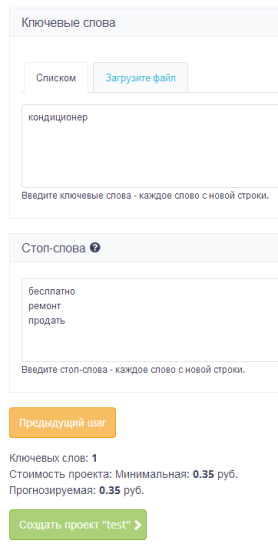 Здесь указываем ключевые слова, по которым хотим получить подсказки. Мы можем загрузить таблицу Excel со списком слов или вписать их сами.
В графе «Стоп-слова» указываем запросы, не относящиеся к сайту, для которого мы составляем семантическое ядро. Rush-analytics не станет собирать подсказки с этими словами.
Система подсчитала стоимость сбора подсказок для одного ключевого слова – 0,35 рубля. Нажимаем «Создать проект» и ждем результатов.
На главной странице «Сбора подсказок» мы видим информацию о проекте – название, дату создания, количество ключевых слов для сбора, статус, возможные действия над проектом.
Здесь указываем ключевые слова, по которым хотим получить подсказки. Мы можем загрузить таблицу Excel со списком слов или вписать их сами.
В графе «Стоп-слова» указываем запросы, не относящиеся к сайту, для которого мы составляем семантическое ядро. Rush-analytics не станет собирать подсказки с этими словами.
Система подсчитала стоимость сбора подсказок для одного ключевого слова – 0,35 рубля. Нажимаем «Создать проект» и ждем результатов.
На главной странице «Сбора подсказок» мы видим информацию о проекте – название, дату создания, количество ключевых слов для сбора, статус, возможные действия над проектом.

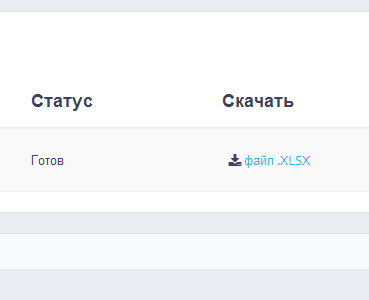 Когда парсинг закончится, статус проекта изменится на «Готов» и нам станет доступен xsls файл. В нем содержатся все собранные подсказки.
Когда парсинг закончится, статус проекта изменится на «Готов» и нам станет доступен xsls файл. В нем содержатся все собранные подсказки.
 По ключу «кондиционер» система собрала 319 подсказок. Полученный файл мы будем использовать в дальнейшем для сбора статистики wordstat и кластеризации.
А представьте, сколько времени бы мы угрохали на то, чтобы собрать подсказки вручную.
По ключу «кондиционер» система собрала 319 подсказок. Полученный файл мы будем использовать в дальнейшем для сбора статистики wordstat и кластеризации.
А представьте, сколько времени бы мы угрохали на то, чтобы собрать подсказки вручную.
 Третий шаг – загрузка xsls файла с собранными подсказками.
Третий шаг – загрузка xsls файла с собранными подсказками.
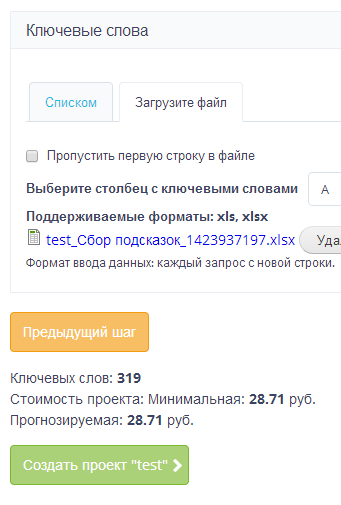 Система подсчитала, что сбор статистики по списку подсказок обойдется нам в 28,71 рубля.
Жмем на зеленую кнопку и ждем заветный файл со статистикой во вкладке проектов.
Вот и он!
Система подсчитала, что сбор статистики по списку подсказок обойдется нам в 28,71 рубля.
Жмем на зеленую кнопку и ждем заветный файл со статистикой во вкладке проектов.
Вот и он!
 Как видите, по каждому из запросов мы получили конкретную статистику по трем параметрам. А затрачено на это дело всего 5 минут.
А теперь представьте, как вы сидите, подбираете запросы с нужной вам частотностью, переносите их в базу. Нажимаете «copy» – «paste», «сopy» – «paste». И так часами стираете пальцы в порошок.
А теперь самое интересное…
Как видите, по каждому из запросов мы получили конкретную статистику по трем параметрам. А затрачено на это дело всего 5 минут.
А теперь представьте, как вы сидите, подбираете запросы с нужной вам частотностью, переносите их в базу. Нажимаете «copy» – «paste», «сopy» – «paste». И так часами стираете пальцы в порошок.
А теперь самое интересное…
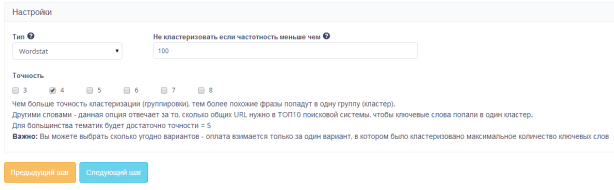 Типы.
Тип wordstat подходит пользователям, которые хотят сгруппировать все запросы из списка.
Другие два типа позволяют отметить в списке запросы с помощью чисел «1» и «0» и выбрать условия кластеризации. Также мы можем не группировать запросы с частотностью, которая нас не устраивает.
Следующий шаг – указание запросов и добавление стоп-слов.
Типы.
Тип wordstat подходит пользователям, которые хотят сгруппировать все запросы из списка.
Другие два типа позволяют отметить в списке запросы с помощью чисел «1» и «0» и выбрать условия кластеризации. Также мы можем не группировать запросы с частотностью, которая нас не устраивает.
Следующий шаг – указание запросов и добавление стоп-слов.
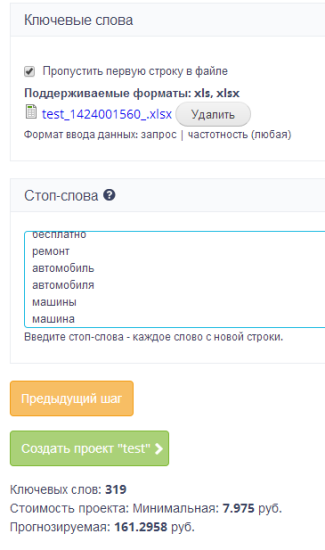 Загружаем файл со списком запросов. Добавляем все слова, которые не нужно кластеризовать.
Система подсчитала стоимость кластеризации. Она составляет 161 рубль.
Кластеризация – наиболее трудоемкий процесс в составлении семантического ядра. Выполнять ее ручками – то еще «удовольствие».
Создаем проект и ждем результатов. Кластеризация проходит в течение 2-3 минут.
Загружаем файл со списком запросов. Добавляем все слова, которые не нужно кластеризовать.
Система подсчитала стоимость кластеризации. Она составляет 161 рубль.
Кластеризация – наиболее трудоемкий процесс в составлении семантического ядра. Выполнять ее ручками – то еще «удовольствие».
Создаем проект и ждем результатов. Кластеризация проходит в течение 2-3 минут.
 В полученной таблице мы видим не только название кластеров и ключевые слова в них, но и суммарную частотность кластера.
Итого…
На получение всей необходимой для создания семантического ядра информации у нас ушло 10 минут. Это в 9 раз меньше, чем, если бы мы делали все самостоятельно без помощи сервиса Rush-analytics. Цена за такое удовольствие умеренная – 188 рублей.
Хорошо иметь такого помощника, не так ли?
В полученной таблице мы видим не только название кластеров и ключевые слова в них, но и суммарную частотность кластера.
Итого…
На получение всей необходимой для создания семантического ядра информации у нас ушло 10 минут. Это в 9 раз меньше, чем, если бы мы делали все самостоятельно без помощи сервиса Rush-analytics. Цена за такое удовольствие умеренная – 188 рублей.
Хорошо иметь такого помощника, не так ли?
Сегодня, я хочу рассказать про автоматизацию этого процесса, а именно Rush-analytics – сервис автоматизированного сбора семантического ядра. С его помощью всего за несколько минут можно собрать подсказки Яндекса и Google, получить информацию о частотности запросов и кластеризовать их. Рекомендую почитать больше про Rush Analytics - цены, инструкции, функционал и многое другое.
В этом обзоре мы протестируем сервис и узнаем, действительно ли он быстро и точно собирает ядро и экономит время веб-мастера.
Оглавление:
Приступим!
Сразу после регистрации на сайте rush-analytics.ru нас ждет сюрприз. Система дарит каждому пользователю 200 рублей на счет для тестирования сервиса.
В интерфейсе сложно не разобраться. В правом верхнем углу информация по аккаунту, состояние счета и дополнительная информация по сервису. вверху слева.
Сбор подсказок
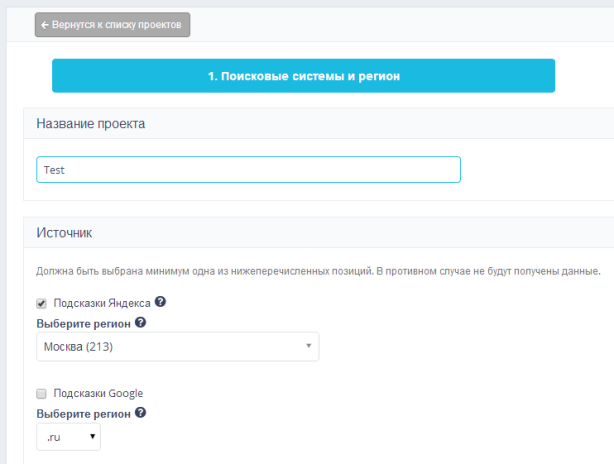
Кликаем на кнопку «Сбор подсказок». Открывается окно «Поисковые системы и регион».
- Вводим название проекта.
- Создаем проект.
Наводим курсор на знак вопроса – открывается желтое окно, в котором указана информация по каждому из способов. Также в этой вкладке мы указываем глубину парсинга.
Изначально глубина стоит на отметке «1». Это означает, что система соберет подсказки лишь один раз, основываясь на заданных вами ключах. Установите «2» и тогда система пройдется по второму кругу, собирая подсказки по ключам, полученным после первого круга.
Оставим все как есть и перейдем к третьему шагу.
Открываем вкладку «Ключевые слова и цена».
Здесь указываем ключевые слова, по которым хотим получить подсказки. Мы можем загрузить таблицу Excel со списком слов или вписать их сами.
В графе «Стоп-слова» указываем запросы, не относящиеся к сайту, для которого мы составляем семантическое ядро. Rush-analytics не станет собирать подсказки с этими словами.
Система подсчитала стоимость сбора подсказок для одного ключевого слова – 0,35 рубля. Нажимаем «Создать проект» и ждем результатов.
На главной странице «Сбора подсказок» мы видим информацию о проекте – название, дату создания, количество ключевых слов для сбора, статус, возможные действия над проектом.
Когда парсинг закончится, статус проекта изменится на «Готов» и нам станет доступен xsls файл. В нем содержатся все собранные подсказки.
По ключу «кондиционер» система собрала 319 подсказок. Полученный файл мы будем использовать в дальнейшем для сбора статистики wordstat и кластеризации.
А представьте, сколько времени бы мы угрохали на то, чтобы собрать подсказки вручную.
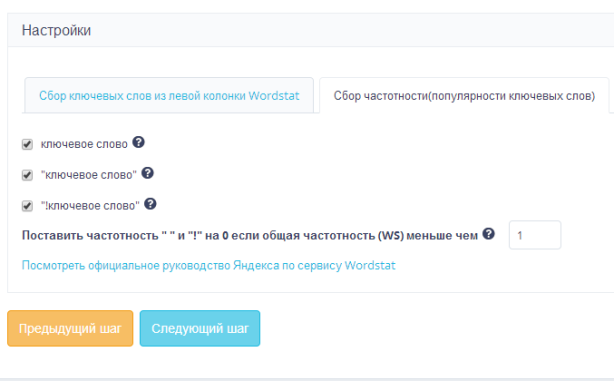
Wordstat
Теперь соберем статистику частотности запросов, которые нам подобрала система. Первый шаг у сбора статистики вордстат такой же, как и у сбора подсказок – даем названием проекту и указываем регион. На втором шаге настраиваем сбор статистики. Указываем, что нам нужна информация:- по общей частотности;
- по частичному вхождению;
- по точному вхождению.
Третий шаг – загрузка xsls файла с собранными подсказками.
Система подсчитала, что сбор статистики по списку подсказок обойдется нам в 28,71 рубля.
Жмем на зеленую кнопку и ждем заветный файл со статистикой во вкладке проектов.
Вот и он!
Как видите, по каждому из запросов мы получили конкретную статистику по трем параметрам. А затрачено на это дело всего 5 минут.
А теперь представьте, как вы сидите, подбираете запросы с нужной вам частотностью, переносите их в базу. Нажимаете «copy» – «paste», «сopy» – «paste». И так часами стираете пальцы в порошок.
А теперь самое интересное…
Кластеризация
Кластеризация запросов — автоматизированное распределение запросов на группы на основе подобия выдачи в поисковых системах. Мы получаем группы запросов и, основываясь на их частотности, решаем, нужно ли создавать под них дополнительные страницы. Достаточно теории. Принимаемся за работу. Указываем название проекта и настраиваем регион. Это мы уже умеем. Далее идут настройки кластеризации.
Типы.
Тип wordstat подходит пользователям, которые хотят сгруппировать все запросы из списка.
Другие два типа позволяют отметить в списке запросы с помощью чисел «1» и «0» и выбрать условия кластеризации. Также мы можем не группировать запросы с частотностью, которая нас не устраивает.
Следующий шаг – указание запросов и добавление стоп-слов.
Загружаем файл со списком запросов. Добавляем все слова, которые не нужно кластеризовать.
Система подсчитала стоимость кластеризации. Она составляет 161 рубль.
Кластеризация – наиболее трудоемкий процесс в составлении семантического ядра. Выполнять ее ручками – то еще «удовольствие».
Создаем проект и ждем результатов. Кластеризация проходит в течение 2-3 минут.
В полученной таблице мы видим не только название кластеров и ключевые слова в них, но и суммарную частотность кластера.
Итого…
На получение всей необходимой для создания семантического ядра информации у нас ушло 10 минут. Это в 9 раз меньше, чем, если бы мы делали все самостоятельно без помощи сервиса Rush-analytics. Цена за такое удовольствие умеренная – 188 рублей.
Хорошо иметь такого помощника, не так ли? Теперь мы есть в Telegram! Самое свежее на нашем канале
0 комментариев
Добавить комментарий
